文章转载链接:https://www.waerfa.com/mochi-diffusion-review
以下是转载原文:
Mochi Diffusion 是一款在 Mac 上原生运行 Stable Diffusion 的客户端,内置了 Apple 的 Core ML Stable Diffusion 框架,以实现在搭载 Apple 芯片的 Mac 上用极低的内存占用发挥出最优性能。
功能
- 极致性能和极低内存占用 (使用神经网络引擎时 ~150MB)
- 在所有搭载 Apple 芯片的 Mac 上充分发挥神经网络引擎的优势
- 生成图像时无需联网
- 图像转图像(也被称为 Image2Image)
- 在图像的 EXIF 信息中存储所有的关键词(在访达的“显示简介”窗口中查看)
- 使用 RealESRGAN 放大生成的图像
- 自动保存 & 恢复图像
- 自定义 Stable Diffusion Core ML 模型
- 无需担心损坏的模型
- 使用 macOS 原生框架 SwiftUI 开发
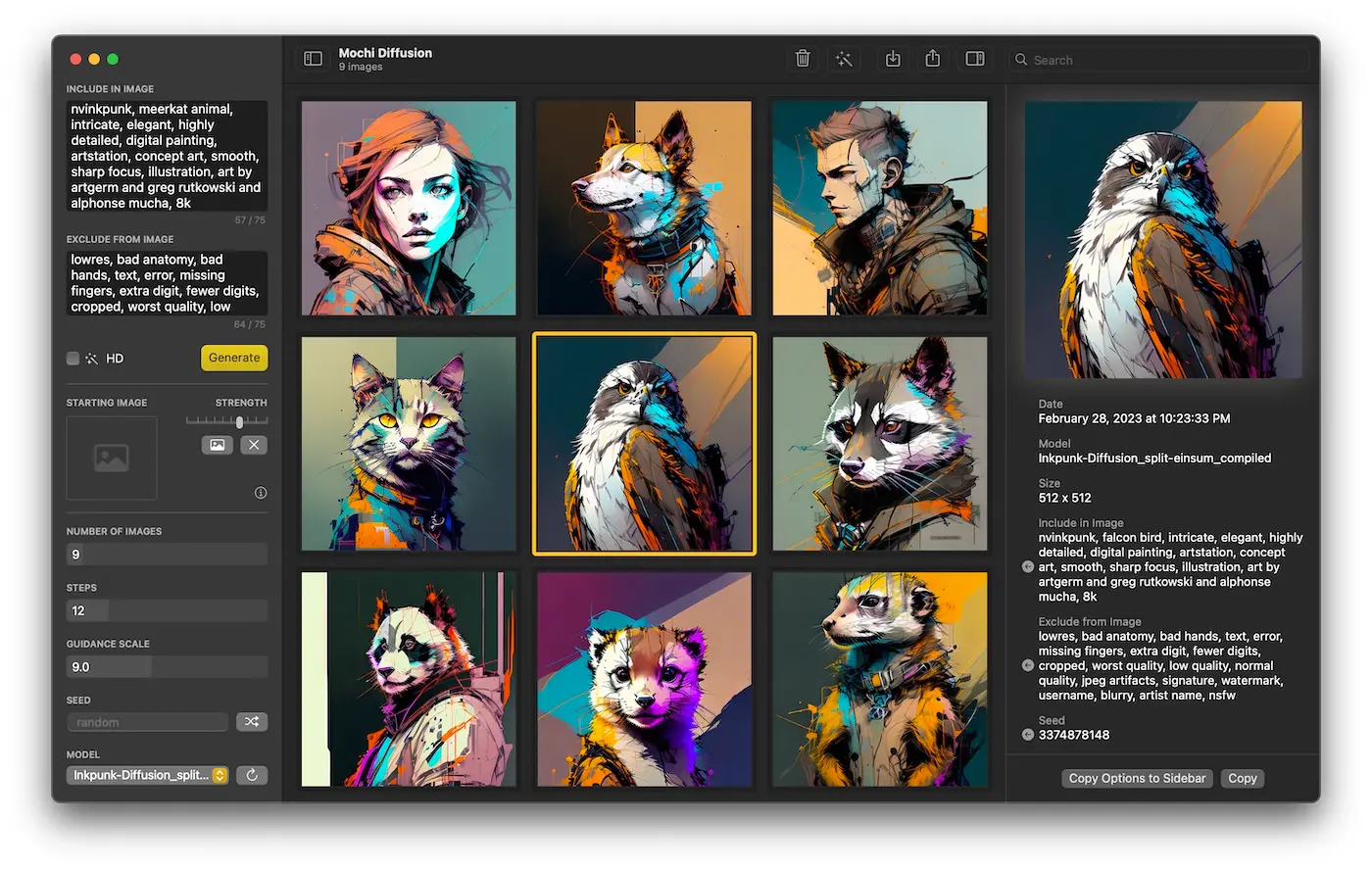
Mochi Diffusion 的使用逻辑很简单,下载、安装、启动,在左边栏输入你的文字描述,可以是语义式,也可以是关键词堆积,还可以填写排除关键词,以更精确的生成你想要的图片,可以是否为高清、有些模型还可以允许你上传一张参考图片,尺寸是 512×512,图片生成的数量、迭代步数、关键词权重都可以自定义。
但是模型的选择很重要,每一个模型都有自己擅长的风格和领域,Stable Diffusion 有非常丰富的模型供用户选择,如果你不知道怎么构建、转换模型,可以直接在 huggingface 下载这些模型,这些模型也是在不断更新迭代的。
进入这个页面:
拉到页面底部,可以看到不少模型。
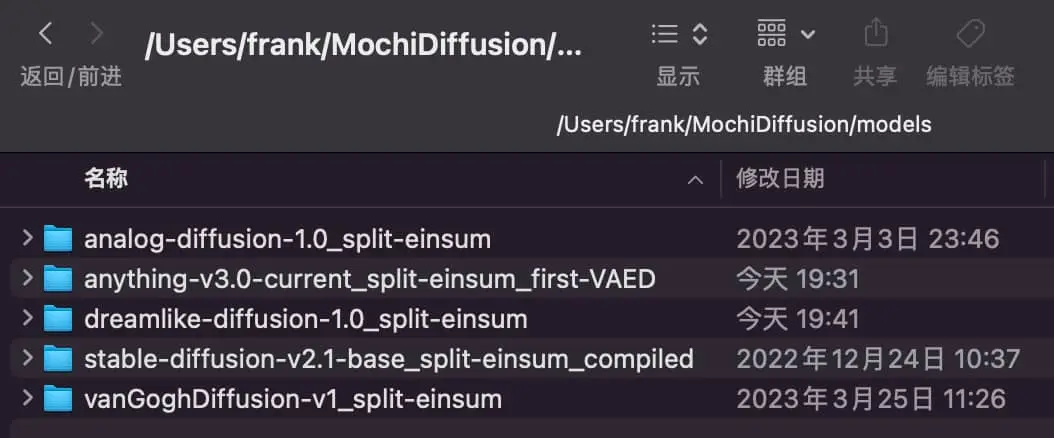
这些模型下载后都需要解压缩并放在 Mac 本地这个目录,你可以像我这样挑选几个比较有代表性的模型试试,每一款的主页都有案例图可以参考。
点击模型名称进入主页:
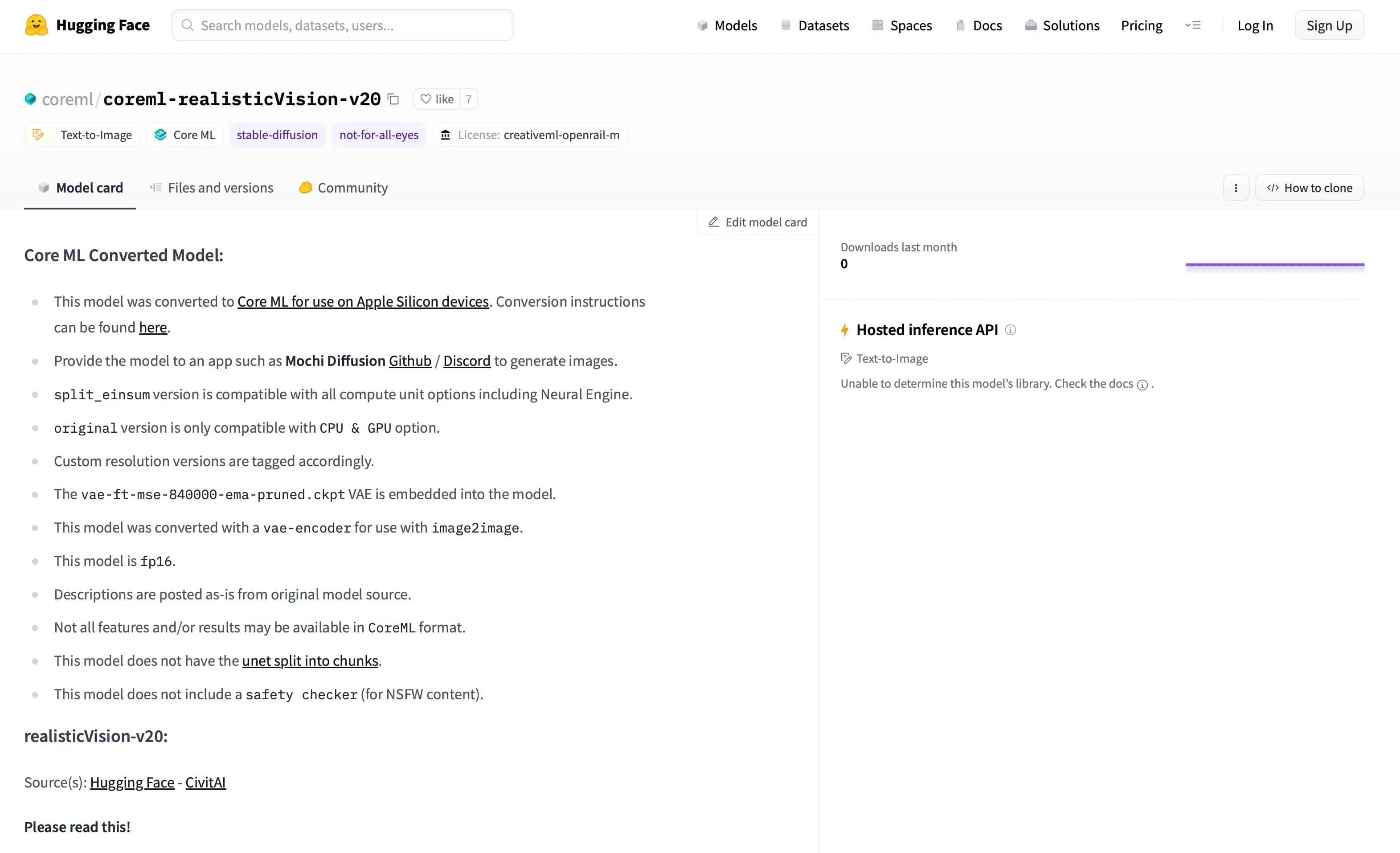
每一个模型主页都有 sample,可以看出这个模型的风格,就是动漫的,图片底部是关键词

将目光移动到 Files and versions,Apple 芯片选择目录里的 split_einsum 目录,点进去。
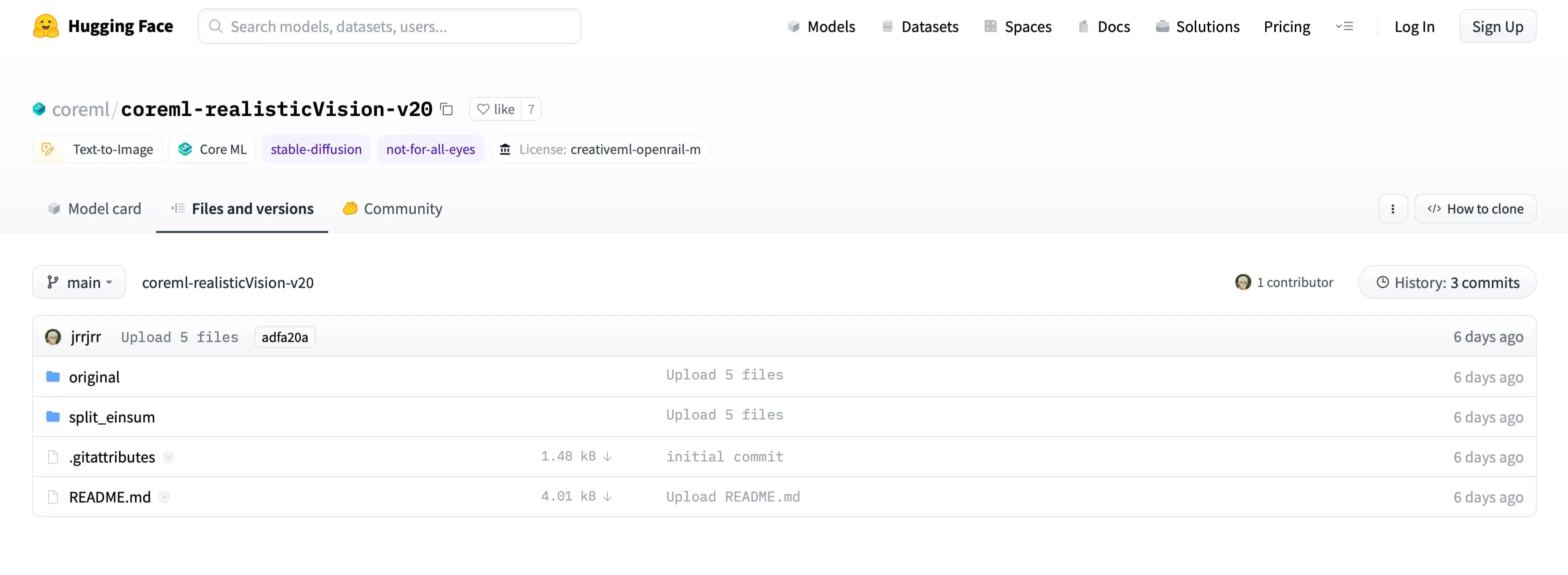
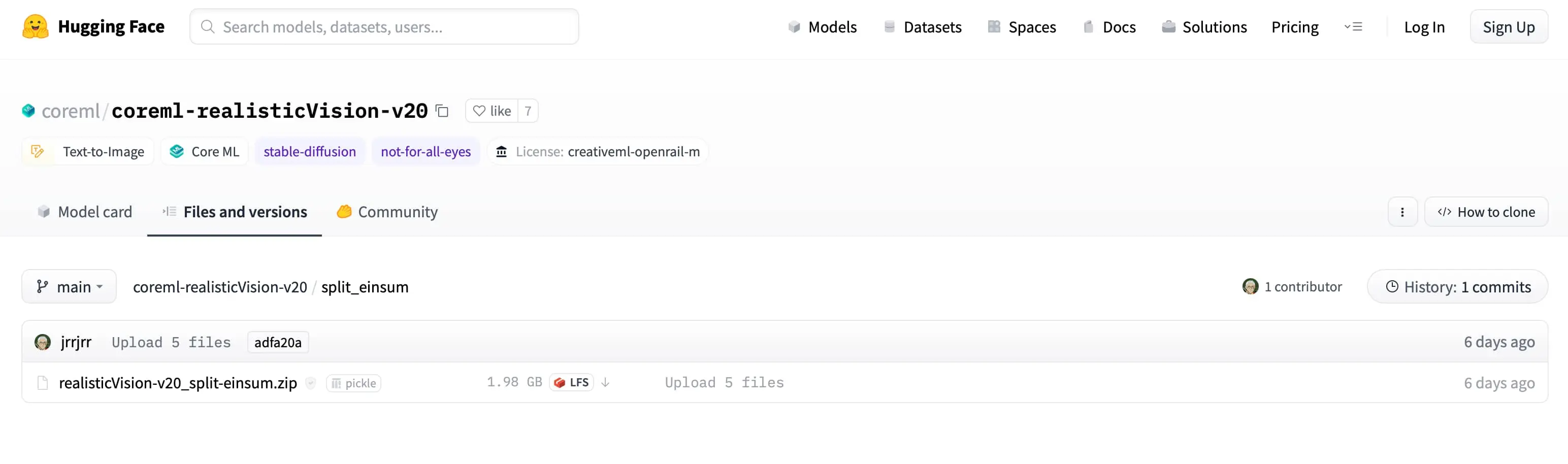
然后就能看到这个模型的压缩包了,点击右侧的下载箭头开始下载,一般这类模型都是 2GB 或者更大的,下载速度还可以,但必须挂那啥才行!
下载好模型,就像前面说的解压缩放置在 Mochi Diffusion 的 Models 目录即可,在初次运行模型时, 神经网络引擎可能需要约 2 分钟编译缓存,后续运行速度会显著提高。一张图片正常 5 秒就会出来。
以下是我用 stable diffusion base v2.1 的模型生成的一个古典式的德国女人,金发蓝眼睛,但是得到的图片显然不是我想要的,因为我的本意是想要一张典型的德国女人图片,所以我换了一下模型并更新了关键词。
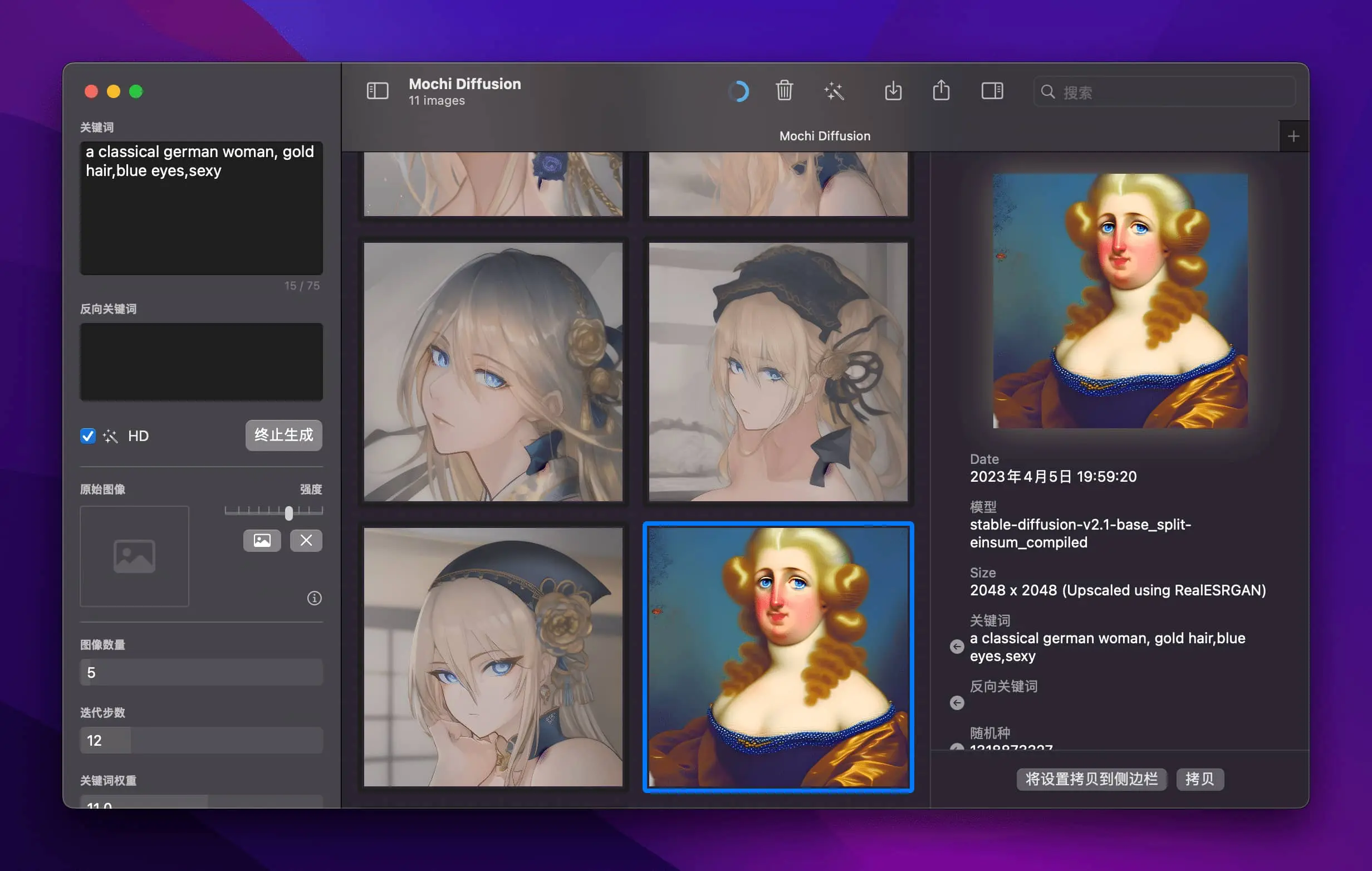
但是效果还是不好,这个模型总是生成日本动漫风格的欧洲女孩形象,我还加了 no japanese style,还是不行,然后我又换了一个模型 Realistic
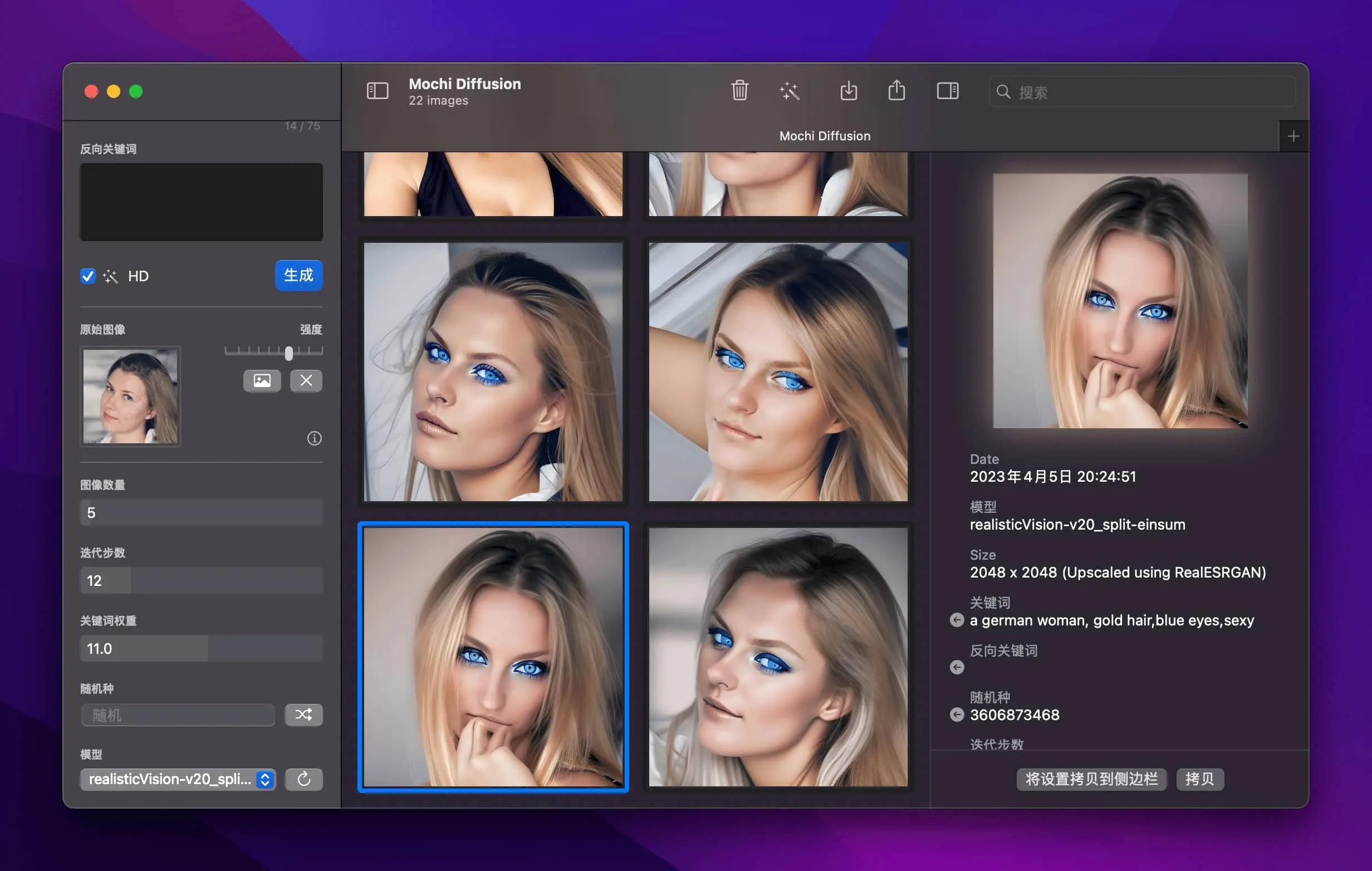
这次加了一张参考图片,谷歌找的,关键词改成了 a german woman,这回行了,不过这个蓝眼睛也太夸张了,还得继续调教,我看网上别人通过 Stable Diffusion 训练出的模型,那个图片相当的写实,看来我还得多学习!
如果你正在研究 AI 画图欢迎在评论区与大家分享经验,在接触 Stable Diffusion 之前我先用的 MidJourney,但这款产品我感觉并不好用,而且试用版不让出图片了。
注意:使用 Mochi Diffusion 需要确认以下环境具备:
- Apple 芯片的 Mac (M1 及更新)
- macOS Ventura 13.1+
- Xcode 14.2 (自行构建)
关于 Stable Diffusion
在苹果设备上运行 Stable Diffusion 和 Core ML + diffusers 生成的图像。
苹果在 macOS 13.1 和 iOS 16.2 中发布了针对 Stable Diffusion 的 Core ML 优化,并通过一个代码库对部署过程进行了详细讲解。
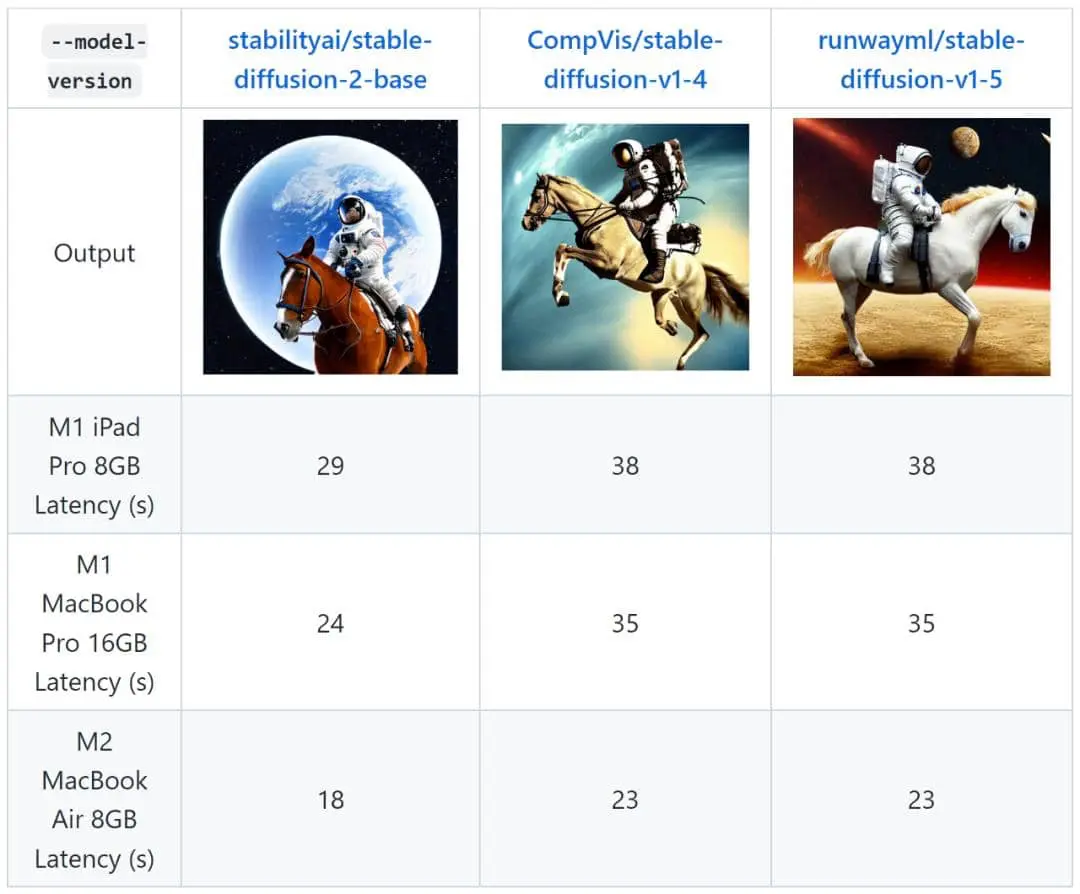
在三款苹果设备(M1 iPad Pro 8GB、M1 MacBook Pro 16GB、M2 MacBook Air 8GB)上的测试结果表明,苹果推出的相关优化基本可以保证最新版 Stable Diffusion(SD 2.0)在半分钟内生成一张分辨率为 512×512 的图。
对于苹果的这一举动,不少人感叹,一个开源社区构建的模型已经优秀到可以让大公司主动采用,确实非常了不起。
另外,大家也开始猜测,未来,苹果会不会直接把 Stable Diffusion 放到自己的设备里?
为什么要让 Stable Diffusion 可以在苹果设备上运行?
自 2022 年 8 月首次公开发布以来,Stable Diffusion 已经被艺术家、开发人员和爱好者等充满活力的社区广泛采用,能够以最少的文本 prompt 创建前所未有的视觉内容。相应地,社区在几周内就围绕这个核心技术构建了一个包含扩展和工具的庞大生态系统。Stable Diffusion 已经变得个性化,而且可以拓展到英语以外的其他语言,这要归功于像 Hugging Face diffusers 这样的开源项目。
除了通过文本 prompt 生成图像,开发人员还发现了 Stable Diffusion 其他创造性的用途,如图像编辑、修复、补全、超分辨率、风格迁移。随着 Stable Diffusion 应用的增多,要想打造出任何地方的创意人员都能使用的应用程序,就需要确保开发者能够有效地利用这项技术,这一点至关重要。
在所有应用程序中,模型在何处运行是 Stable Diffusion 的一大关键问题。有很多原因可以解释为什么在设备上部署 Stable Diffusion 比基于服务器的方法更可取。首先,终端用户的隐私可以受到保护,因为用户提供的作为模型输入的任何数据都保留在用户自己的设备上。
其次,在初次下载之后,用户不需要连接互联网就可以使用该模型。最后,在本地部署此模型能让开发人员减少或消除服务器方面的成本。
用 Stable Diffusion 产出可观的结果需要经过长时间的迭代,因此在设备上部署模型的核心挑战之一在于生成结果的速率。这需要执行一个复杂的流程,包括 4 个不同的神经网络,总计约 12.75 亿个参数。要了解更多关于如何优化这种大小和复杂性的模型,以在 Apple Neural Engine 上运行,可以参阅以前的文章:Deploying Transformers on the Apple Neural Engine。